Herds Of Microservices Flocks Of People
October 24, 2020
Herds of microservices, flocks of people, and those that take care of them
I’ve been in big enterprises, as a day job, for almost 6 years now. I’ve also been working on, and growing, a large scale microservice architecture (about 150 microservices) for about 18 months.
In one way microservices give large enterprises the ability to split large work across a variety of teams with isolated codebases. If the published APIs for these microservices don’t change, none of the producers or consumers into that service care about maintenance or features added to that service.
Yet the working of the product as a whole requires all the micoservices to be deployed, with compatible versions, into the deployment environments.
From a high level perspective it doesn’t matter if these services communicate via HTTPS, protobuf, custom TCP protocols, or message buses like Kafka or an MQ flavor. Microservice A still acts on data that’s supposed to be created by Microservice B, and if it’s not there the user’s going to wonder.
If a user posts a photo on a social network type product, and it doesn’t show up after a couple of seconds the user gets worried. If it doesn’t show up ever - because Microservice A posted the photo to some message queue but Microservice B wasn’t deployed to read and respond to the message - that’s actually a bug. As much as a dialog box in the users face would be.
That dependence: Microservice A requires microservice B, which requires microservice C, all deployed for the product and customer’s user journey to work together, is why it’s called a “herd” of microservices. (or a web of microservices, but herd is the more industry-common name).
First, some enterprise software engineering assumptions
Enterprise software engineering is waayyy different from startups. Before my time in BigCo land I spent a lot of time in “small projects and startups” land.
I enumerate some of this article’s assumptions here, assuming they are close to universal. My sample size is small, but I don’t think I just got (un) lucky in my experiences:
- Of > 500 engineers. Some of which work on things totally unknown to you!
- codebases owned by teams. (Because in BigCos having a thing owned by a single person makes people antsy, at least in the BigCos I’ve been in. And having a single group of people makes it easy to page them).
- Multiple teams per end user project.
- The enterprise is now trying to - or successfully have - transitioned to microservices.
- Unified discovery or apparent similar route (“oh look the /search api!“. Maybe behind the curtain it’s 5 teams with 20 microservices or lambdas - whatever, the caller doesn’t know or care)
- Microservices can be grouped by what downstream or peer services they call or rely on. (The next section will talk about this cluster or “clique” effect)
Note: it’s possible - but exceptional - for a microservice to not have an owner. Perhaps the team owning it all got laid off, or all quit before replacements could be hired. From a corporate perspective this is bad - a year or two from now when that microservice breaks, you’ll have a game of hot potato around who needs to fix it… on the double because there’s some customer facing bug. It’s also, very likely, making teams that depend on those microservices nervous, because, “ummm, who is maintaining the Ad Data Repository that we interface with? Ummm…”
Likewise, it’s possible - but should be exceptional - for a microservice to have two owners. In my experience this means you’re either starting to rebuild a monolith, or introducing situations where Team A doesn’t want to deploy but Team B does.
Turning the microservice herd on it’s head: it’s clusters of people (teams)
If we consider all the microservices required for a product - or products - to be a herd of microservices you’ll notice something. You’ll notice that these herds form microservice cliques - the login service only talks to the auth database and the email service, but never the file upload service, for example.
Additionally (because this is the enterprise) teams, not individuals, own services. A team may potentially own the majority of services in a clique, or a couple of cliques. If the enterprise is wise there may be some domain drive design modeling going on to better classify these cliques.
I suspect there are three, maybe four, ways to split up the enterprise to serve a product (or multiple products).
The Ways I’ve seen enterprises organize teams, products, microservices (and thus your herds and cliques)
Note that the stars in these pictures may be microservices, but could be front end library components.
Single product, layered approach
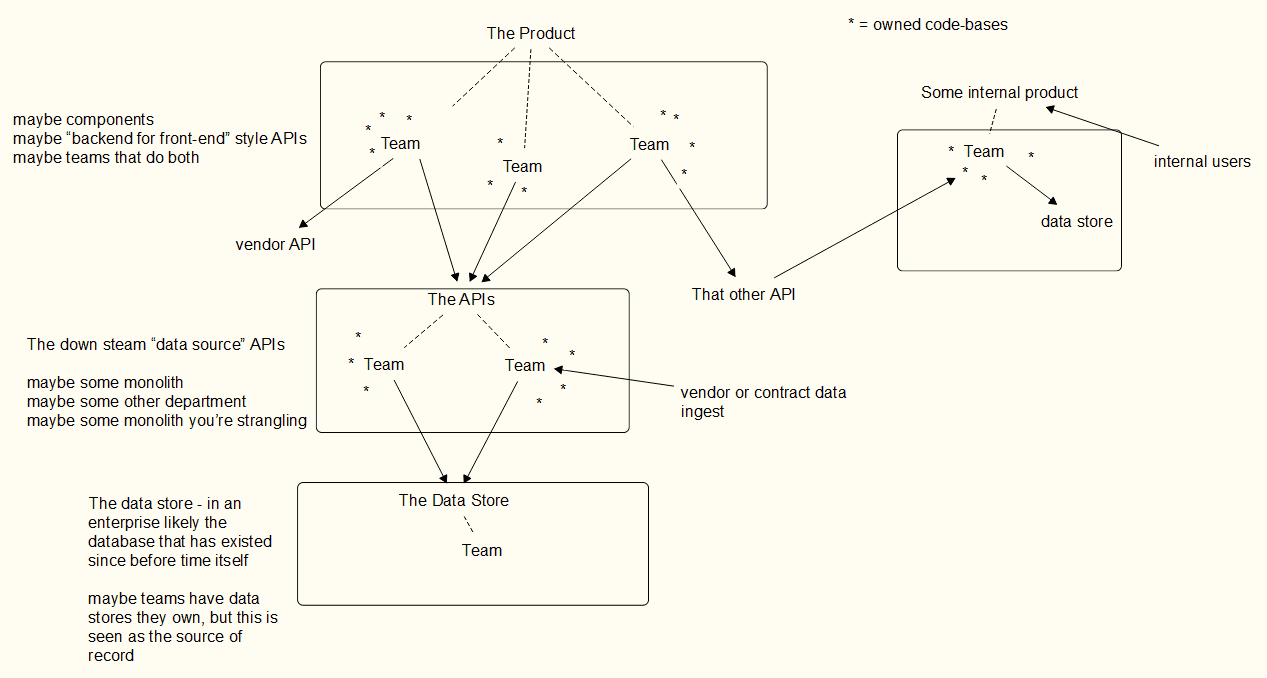
This organization has teams close to the user, and teams creating services uncoupled from any one product. Imagine the teams working on our social media app, and the a “data platforms” team that handles hard data storage, vendor data imports, or interfaces to the real source of records.
This is very likely Conway’s Law at play: the database team maintains the big database, and (because enterprise) everything currently flows through the big database. This big database is the Source Of Record.
Another lens
Scaling Teams talks about these teams as potentially being part of a platform. Platform in the most generic of words: “the iOS team”, “the web team”, “the android team”. The “APIs” are provided by folks working on “the backend team”.
Yet the diagram still works for this structure of teams. Chapter 7 of Scaling Teams touches on several themes also in this blog entry.
Many products, layered approach
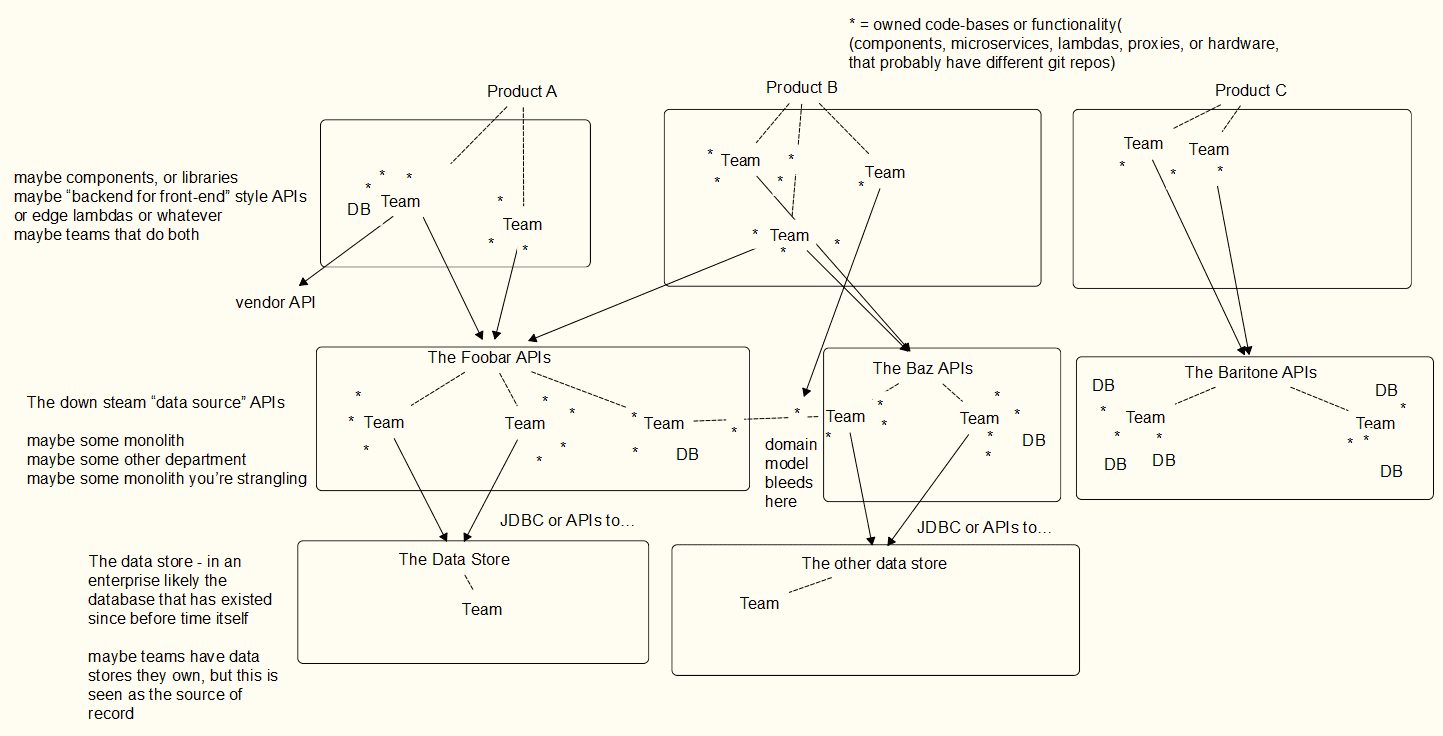
Here we have multiple products. Notice that some products aren’t connected to the rest of the herd. Product B is somewhat connected: think how Instagram uses Facebook for authorization, but that’s it.
Cross functional teams
Cross functional teams aren’t super new - I heard about them when I was in Total Quality Management classes in college.
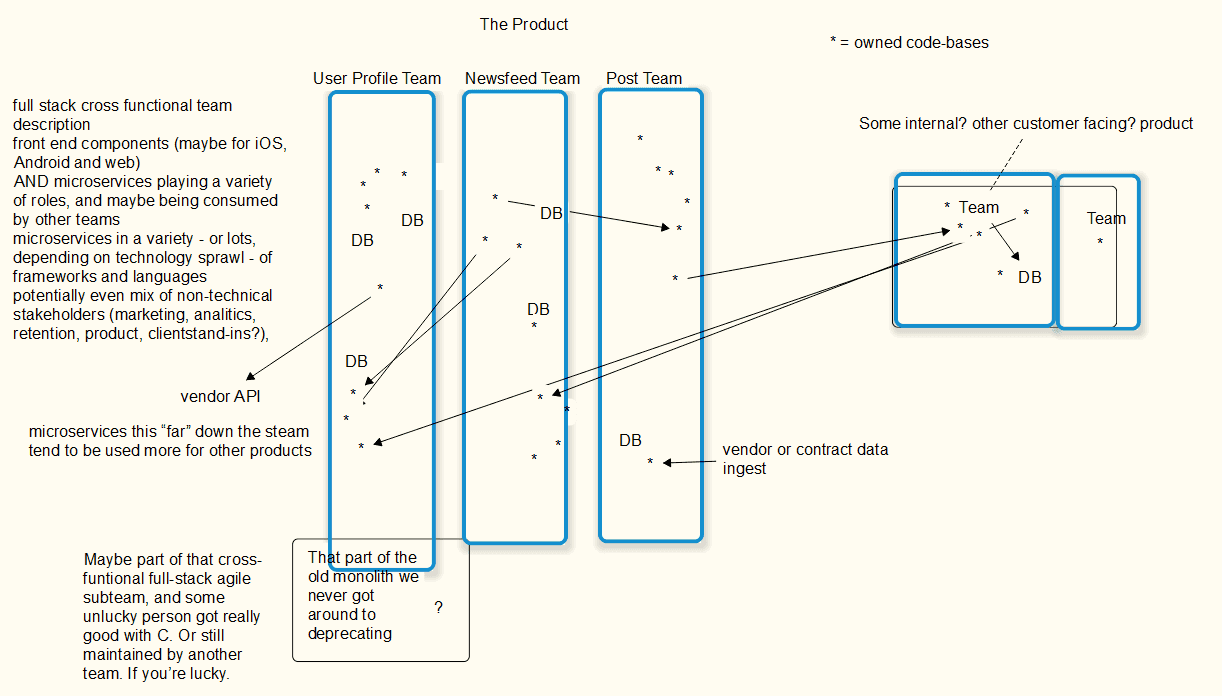
But the idea here is that a “two pizza team” should be empowered to change everything about some sliver of functionality from the UI all the way down the stack. Because - an often quoted definition - an agile feature isn’t shipped until a user sees it.
I would also posit that these cross-functional teams don’t break Conway’s Law, but may graft a cross-functional layer on top of the existing org structure.
Likewise, I suspect this approach means you have an implicit layered model too. Perhaps you have services created using the Backend For Frontend design pattern. Our example social media enterprise might have a BFF microservice that supplies data for the mobile app, and a “data layer” service… which a BFF microservice for the Alexa app uses. I attempt to illustrate that in the diagram, in fact.
I’m not convinced GraphQL solves this problem either - you may have queries and mutations used heavily by some other team too.
Conclusion
Regardless of how your org chart really looks, if - and since - teams are coupled to microservices you can either make your system design look like your org chart or facade over that org chart. Either way you can draw a box around microservice owners and (hopefully!) find edges of parts of your business domain. Or, if that doesn’t work, find the cliques and draw boxes around them.
on data, technical debt as a metaphor, and other cross cutting concerns
Take a look back at those diagrams. Notice the different database organizations of the various structures. A layered organization will likely have only one or two databases controlled by the product teams (for “closeness of data” or “only we care about this particular part of the data”) where the teams downstream are the “source of record”.
In a fully cross-functional example there is no “downstream”. Yet the organization still has data to store, maintain and guard. Teams may create a database or two, or one per microservice, to store this data. Yet I would argue that “data standards” is an enterprise wide concern. Is the data secured in transmit and rest, potentially using approved data storage tech, with proper access rights? No enterprise wants a privacy leak and lawsuit like Target or Equifax.
So, how does an enterprise, or a group of teams working on a single product inside the enterprise, establish data standards?
Likewise, how does “technical debt” - perhaps “oh yeah we should secure this database, it’s some technical debt we need to clean up” of a microservice, of a clique, affect the herd? Or the product? Or the business?
In fact, I’m starting to dislike the analogy of technical debt, and starting to lean into the idea of the functional capability of a system.
In the US there’s often both bad roads and lots of road construction, so the model of functional capacity of a system being a road to deliver the customer journey feels natural to me.
If our journey is to drive features to the customer, then we want well paved roads so we can drive quickly, not dirt roads where 35MPH is all you can go. We also want certain, built in, abilities of the road: smooth ride, experts on call in case we break a tire (or a database!), and potentially some kind of guidance to ensure our car is safe to use on the road and not harming others or the environment (like spewing customer data everywhere).
This is the topic of a future blog post: roads and feature capacity of microservice herds. Which will be a much easier conversation to have now that we understand microservices, cliques, herds, products, teams, and how enterprises mash those concepts up in different ways.