Software projects and planes of growth
November 14, 2020
Introduction
In my previous blog article I said:
This is the topic of a future blog post: roads and feature capacity of microservice herds. Which will be a much easier conversation to have now that we understand microservices, cliques, herds, products, teams, and how enterprises mash those concepts up in different ways.
Before that we need to examine the phases of a software project’s growth. What are the technical steps a project goes through to go from the first line of code typed through initial testing to customers seeing the project?
In fact, don’t let that term “microservices” fool you: I suspect these phases of growth apply to software projects in general! (Excuse my current backend or full-stack-web terms sometimes!)
Planes of growth
Lets scope our conversation to a single codebase for a minute - no microservice herds or multiple teams. How a service goes from the first engineer typing code to used by a user.
There’s of course the Software Development Lifecycle often simplified down to Planning -> Analysis -> Design -> Implementation -> Maintenance. That’s a pretty simplistic model for today’s agile ship to the customer, full stack development, startups vs enterprises microservices world.
If we look outside tech for a minute we may get our good answer: Children have certain growth milestones - some teaching practices call these “planes of development”. Codebases too have planes of growth, from pure greenfield innovation to business as usual.
(We also have the the PMI project maturity model: Initial -> Repeatable -> Defined -> Managed -> Optimizing. This might work better in enterprise-land, but in startup-land a bunch of work, maybe even years of work, can happen in those first three steps.)
I believe there are five steps in modern codebase growth: foundations -> testing -> specialization -> process / stabilization -> self actualization.
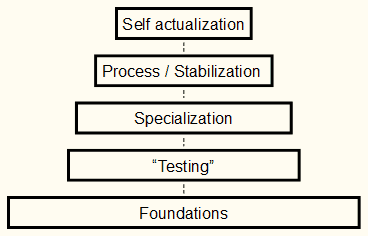
These steps, like Maslow’s Hierarchy of Needs, are steps you can regress on. Imagine you start a project, a single application, in Scala, but 3 months in your Scala person gets tired, bored, distracted, busy, or needs to take paying or better paying work. (I’ve seen - and been - all five!). Well, now the remaining founders are looking for Scala people to join the project, or maybe have fallen back to the bottom step: pick some new foundations.
(Startups, pay your people and pay them regularly - or know your horizons may be short. Developers in early stage startups: pick what makes you comfortable, but maybe not too far down the TIOBE index if you can help it, yah?)
Also like Maslow, the issues at lower levels affect your performance at higher levels. If home is not safe, or not stable (the roof leaks, the mortgage is late, or you’re living out of your car and taking showers at the Y) that sucks up energy and time you don’t have for other parts of your life. If there’s a very odd bug in the compiler for a language or tool you’re using, you’re going to have to fix that before you can ship features to customers.
Step 1: Foundations
Not all programming languages are equal, and not all teams are equal. What’s the best language for your needs, your team (if you have one) or your situation?
As a bit of a polyglot myself, when I work on a new personal project I’ll tend to pick implementation language by the tools that language has that matches my needs. Maybe that’s a builtin tool, maybe it’s a third party library, or a paradigm that language does well.
However, when picking for a greenfield project for clients or employers I may look at other things: availability of people familiar with the language in question, common use of that language in the programming community, or languages I know can do the job (not “Hmmm, I’ve never used C++ for web apis before, this greenfield would be a great time to try”). I’m very rarely going to pick obscure languages for a startup because it’s hard to find people in general for startups, and finding someone with OCAML experience too makes it impossible.
Next, do you have data to store? What kind of data is it? Do you put it in a relational database, or an object database? This may influence your framework or language. How are you going to deploy this, and how much do you want to pay for hosting? Is this for public, or only private, consumption? How do I mitigate potential DDOS or not go down if I go viral?
If it’s a desktop or mobile application: how may platforms do you have to support? Can you use some cross-platform toolkit, or does that not give you results you like? Do you want to try sharing code?
All of these considerations before a single line - or many lines - of code is written.
You don’t want too many developers in this stage, likely less than 3. I’ve likened this stage to a very small kitchen: ever been in one of those kitchens where there’s barely enough room for three people to turn around? Even tried to have those three people working on separate things in that kitchen? Especially when one is trying to start baking, one is building shelves and floors to extend the kitchen out to the front lawn, and the third is working on prepping salad fixings (with plenty of trips back and forth to/from the fridge!)
Sometimes a project can stay in the R&D phase for a long time, like some work I was doing on an application to support a prototype electric musical instrument. Couple of big setbacks to that project, as we learned what did, didn’t, couldn’t, and what written code wouldn’t work in practice.
Here is the step for carefully knowing what You Ain’t Gonna Need at this point, and what is critical. For example, do you need to think about a microservice application architecture at this point? Likely not (unless you know, know, know, because your boss at a BigCo has multiple million dollars of budget in their hands). When I was doing early stage startup work I usually preferred to start work in a single repository for the project. This shows my Rails background of course, but I’m not convinced the benefits of microservices beat the drawbacks in projects of younger than a year, with less than 5 people and with less than 5,000 lines of code in the entire startup. (See also: MonolithFirst)
So what do you optimize for, and what do you not? Hyperscaling? Stable, long term development on a large codebase? Hypergrowth? All your friends are wizards with Symphony, so you have technical support / future headcount? Your software needs to run on a cluster of Raspberry Pis? All these questions lay down the foundations of the project, and solid foundations make house construction go faster.
Step 2: Testing (whatever that means to you)
I use automated testing as the basis of my development work, but this level doesn’t just mean automated testing. It could be human testing: deploying your work somehow, somewhere so people other than the developer can use it, poke it, test it, show it, etc.
For me this step usually involves setting up some kind of build pipeline too (CI/CD), mostly through my own failings of too many languages in my head and I’ll never remember the steps to correctly deploy this if I don’t hook it into some kind of automated test solution almost immediately.
This could mean laying the seeds for a testing culture. Perhaps you lay foundations to use BDD, or frameworks around UI testing a frontend application.
Step 3: Specialization
You may get more people at this point. Where previously one person was doing “it all”, maybe you have three or four developers.
This is also the point where specialization likely happens. Sure you’re hiring full stack developers, but you notice that Mark tends to pick up the work involving design a lot (he’s been dreaming about a unified visual design system), and Heather picks up work around the workflow engine. That’s interesting…
If it’s a backend project, here might (but not always) be where you want to consider a couple of microservices at this point, and not just a single monolith. Usually either when people are complaining about lots of merge conflicts, regressions, tests taking too long, or an obvious area in the codebase can be separated out. (Usually “user notifications and alerts” is about the first piece identified.)
Something to also look for, on the “split things up into multiple microservices” front are “how hard are merges”, talked about on my friend Dave Aronson’s blog on breaking up a Rails app into Rails engines.
On a separate note, startups tend to release somewhere in here.
Step 4: Process / Stabilization
The project has hopefully stabilized at this point, and if it hasn’t then you’re not at this stage.
On getting to stable
I’ve seen projects where the client either changes their mind every month (with a change that would result in a relatively large bit of re-work), or discover new aspects of the product to be implemented. This is not stabilization! It’s especially not if developers are saying, “That’s going to require a large refactor”.
Sometimes these changes are obviously big - “our users want chat functionality, in addition to everything else!” Sometimes these changes can seem small, but have drastic changes. My favorite example is a client where we asked, “Can the user only ever have one of these things?” Answer back, three times, was “Only ever one”. A month later: “Ohhh… well, they actually might have two”. From a data modelling perspective this was a big change!
I also believe you need technical stability before any Agile progress (like Scrum) will help you predict real world schedules. Here’s why:
A project in my past - a very R&D project - was working along when we discovered a foundational data modelling problem. This data modelling problem was so foundational it sent the team into a conference room to think deep thoughts and do whiteboard work for a month.
Even if we did have Scrum velocity numbers before that, fundamentally reworking our data model both turned any kind of project wide burndown chart flat (decoupling it from any even projected deadline!) and meant we had to spend a couple weeks on a large refactor to move our (busted) data model to the new solution.
Stabilization means your Scrum metrics / velocity start making more sense
Sometimes the ceremonies built into Scrum, the work towards understanding a team’s velocity, are meant to both make software more predictable and to communicate impediments quickly. But without a stabilized development I’m unsure if some of that veneer is helpful.
Another team in my past used Scrum methods to arrive at a commitment for a sprint. I sat down to do my work, and - turns out - I discovered one or two dependent stories I had to pull into the sprint. Those stories had additional stories I had to pull in, and I turned out to be about 4 stories deep away from what I initially set out to do.
Theoretically that scenario could have gone one of three ways:
- Me alerting the PO and the scrum master removing tickets from the sprint to compensate for the additional found load
- Me alerting the PO and the scrum master saying, “Ok, whatever, it’s all made up and the points don’t really matter, rollover happens, whatever”
- Me alerting the PO and the scrum master, them saying, “Oh well, we need these features by this date, too bad so sad looks like you have work to do”
This exact scenario is why I dislike the word “commitment”, and was extremely happy when the Scrum Alliance changed it to forecast in their vocabulary. The weatherperson does not commit to it raining this afternoon - they forecast it (and are sometimes wrong).
In these two scenarios (rethinking the data model and pulling in all those dependent tickets) the software is not even a little bit predictable - they were too much in the research phase of “research and development”. In one case, technical research, in another case product research.
I would argue that the best teams, even in stable “the customer and tech is mostly well understood” mode, may still under estimate, occasionally, by up to say 30%. But 30% is a far cry away from everything consistently taking 3 times as long. From a technician standpoint, a lot of Scrum ceremonies are probably a waste until you can make one or both of those items (tech requirements and feature requirements) become consistent.
Enterprises tend to create agile teams with agile processes - potentially even the same agile process - for all teams, in the Foundations step. Startups probably won’t even think about introducing a process until (about) here because they (instinctually or through experience) know that useful predictability likely won’t happen until at least this point. Then again, there might be wisdom in, during earlier phases, taking more of a process then you really need and growing into it, then letting those guardrails guide you into maturity and predictability eventually.
On Stability and Chaos in a microservice herd
If you do split “the team” into multiple flocks of people - for example, because you split your project into 4-5 or more separate codebases back in the specialization stage - you might start thinking about separate sub-teams to manage the work.
However, a caution here: splitting everything up before the stability step means you have distributed chaos, not centralized chaos. You have Team B complaining that Team A isn’t delivering a feature they need, but Team A had to pull an additional 5 tickets into the sprint to get it done…
With a single project under one roof it’s easy to see the roadblocks - they’re probably in a couple people’s heads at a couple different levels. (The Scrum Master knowing these two things are dependent, some senior engineers that see the problem and solution, etc). Chaos, if there is any, is centralized under a single team.
When a project is broken up into multiple sub-teams there’s the chance to create distributed chaos.
With distributed chaos maybe a dozen people have non-overlapping parts of the state of the project in their head. This might appear as lots of impediments being filed on all of the teams (as technical or product level churn happens), incident rates going up, a mysterious increase of problems where it’s not just one team’s fault but a fault caused by three different teams (or microservices!) not talking to each other well, blockers, missed deadlines causing a cascade of missed deadlines, bad morale (especially inter-team moral!) and “unmet forecasts”.
Sure, build the airplane on the way down, but having 4-8 scrum masters screaming that they can’t test anything because no team has come together on a hint of a deployment strategy (“can we at least agree that all this is going to be deployed on AWS?”)… is not great. (I’ve been on both sides of this…)
Step 5: Self Actualization
At this point you’re delivering features that are approximately known: very rare is a huge brand new part of the app announced (at least not every week!) and technical churn in the codebase has potentially calmed down too.
Enterprises tend to release here.
Like Maslow, it is possible for projects at this level to fall back down to previous steps. A refactoring to clean up technical debt or provide better operational monitoring is (likely) not it… but say Apple deprecating OpenGL where your game uses only that to render, yes that will be a very bad time.
You may ask, “well, what kind of activities does a self-acualized repo partake in?” Larger stabalizing efforts as part of a larger enterprise, leading “economies of scale” initives bigger than the single project. If the human caused process and stress is under control (and only then!) could you introduce something like choas engineering. (So not introduce more choas into an already chaotic system!).
Conclusion
I believe all projects take this journey.
In an established microservice/backend project with multiple teams and multiple deployed microservices, the project could (and probably should) realize that at least all the microservices in this project have approximately the same characteristics. We can - and probably should - assume that in a large enterprise commonalities may be very small, but that inside a project you likely can assume the microservices all mostly act the same way. (Be that microservices that query other APIs and transform it, or APIs that listen for data on some evented Kafka bus, transform it and then probably write it to another topic).
The less teams have to invent code at the Foundations or “Testing” levels (or code given to them by other teams!) the greater their end-user feature capacity is.
This is your feature capacity road: how many decisions can the architects of the system solve so the development teams don’t have to ask those questions. “How do we do CI/CD?” “Here’s an answer”. “How do we deploy this thing?” “Here’s an answer”, etc etc.
For every new microservice that joins the herd, or a team/clique, how quickly can you bootstrap a standard microservice (whatever that means to your project!) through these planes of growth?
Even just that use case is a great way to increase - an enterprise project with many teams contributing to microservices in the herd - ‘s productivity…